728x90
반응형
Doker
- Doker : 컨테이너 기반의 가상화 시스템
- Container : os 는 하나로 두고, 필요한 부분만 가상화 한 시스템
Tensor

- squeeze, unsqueeze
x = torch.FloatTensor([[0],[1],[2]])
x.shape()
x.squeeze()
x.squeeze().shape
--------------------------------------
tensor([[0.],
[1.],
[2.]])
torch.Size([3, 1])
tensor([0., 1., 2.])
torch.Size([3])- float, long, byte tensor
lt = torch.LongTensor([1,2,3,4])
print(lt)
print(lt.float())
bt = torch.ByteTensor([True, True, False])
print(bt)
------------------------------------------
tensor([1, 2, 3, 4])
tensor([1., 2., 3., 4.])
tensor([1, 1, 0], dtype=torch.uint8)- concatenate, stacking
x = torch.FloatTensor([[1,2],[3,4]])
y = torch.FloatTensor([[5,6],[7,8]])
print(torch.cat([x,y], dim=0))
print(torch.cat([x,y], dim=1))
x = torch.FloatTensor([1,2])
y = torch.FloatTensor([3,4])
print(torch.stack([x,y]))
print(torch.stack([x,y], dim=1))
------------------------------------
tensor([[1., 2.],
[3., 4.],
[5., 6.],
[7., 8.]])
tensor([[1., 2., 5., 6.],
[3., 4., 7., 8.]])
tensor([[1., 2.],
[3., 4.]])
tensor([[1., 3.],
[2., 4.]])- cpu의 tensor와 gpu의 tensor 연산은 error가 발생한다. 장치를 통일해야 한다.
- in-place operation
x = torch.FloatTensor([[1,2],[3,4]])
print(x.mul(2)) # [[2,4],[6,8]]
print(x) # [[1,2],[3,4]]
print(x.mul_(2)) # [[2,4],[6,8]]
print(x) # [[2,4],[6,8]]Linear Regression
- linear regression : 학습 데이터와 가장 잘 맞는 직선을 구하는 일
$$ y = Wx + b $$
optimizer = optim.SGD([W, b], lr=0.01)
optimizer.zero_grad() # gradient 초기화
cost.backward() # gradient 계산
optimizer.step() # gradient 개선
- hypothesis = H(x) = Wx + b
- linear regression 모델 작성
x_train = torch.FloatTensor([[1],[2],[3]])
y_train = torch.FloatTensor([[1],[2],[3]])
W = torch.zeros(1, requires_grad=True)
optimizer = torch.optim.SGD([W], lr=0.15)
for e in range(epoch+1):
hypothesis = W*x_train
cost = torch.mean((hypothesis - y_train) ** 2)
print(f'Epoch {e}/{epoch} W: {round(W.item(),3)}, Cost: {round(cost.item(),6)}')
optimizer.zero_grad()
cost.backward()
optimizer.step()
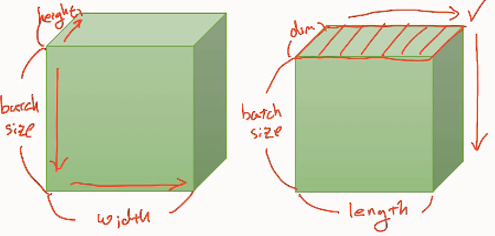
- minibatch gradient : 전체 데이터를 작은 단위로 나누어, 각각을 학습한다.
- Pytorch Dataset
from torch.utils.data import Dataset
class Dataset(Dataset):
def __init__(self):
self.x_data = [[73, 80, 75],
[93, 88, 93],
[89, 91, 90],
[96, 98, 100],
[73, 66, 70]]
self.y_data = [[152],[185],[180],[196],[142]]
def __len__(self):
return len(self.x_data)
def __getitem__(self, idx):
x = torch.FloatTensor(self.x_data[idx])
y = torch.FloatTensor(self.y_data[idx])
return x, y
dataset = Dataset()- Pytorch DataLoader
from torch.utils.data import DataLoader
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
Logistic Regression
- P(x =1) = 1 - P(x = 0)
- W := W - $\alpha$$\frac{\partial}{{\partial}W}$cost(W)
- cross entopy
y_ont_hot = torch.zeros_like(hypothesis)
y_one_hot.scatter_(1, y_train.unsqueeze(1), 1)
cost = (y_one_hot * -torch.log(F.softmax(hypothesis, dim=1))).sum(dim=1)
z = x_train.matmul(W) + b
cost = F.cross_entropy(z, y_train)- CrossEntropyLoss는 내부적으로 LogSoftmax후 NLLLose(Negative Log Liklihood)를 하기 때문에 최종 레이어는 logit으로 둔다 (softmax를 사용하지 않는다)
Tips
- 1 epoch : 전체 데이터를 한번 학습하는 것
- batch size : 메모리와 시간을 절약하기 위해, 전체 데이터를 나누는 크기
- iteration : 전체 데이터를 한번 학습하기 위해 사용한 batch size (data / batch size)
'ML_DL > 딥러닝 공부하기' 카테고리의 다른 글
| [파이토치로 시작하는 딥러닝] Part-3 CNN (0) | 2023.07.02 |
|---|---|
| [파이토치로 시작하는 딥러닝] Part-2 DNN (0) | 2023.07.02 |
| [Loss Function] Cross Entropy (0) | 2023.04.30 |
| [Preprocessing] Categorical Feature Encoding (1) | 2023.04.25 |
| Model Ensemble (0) | 2023.03.24 |